N-step TD¶
1. What is n-step TD
n-step TD lies between Monte Carlo and TD methods. Consider estimating \(v_\pi\) from episodes generated from \(\pi\), Monte Carlo performs an update based on the entire sequence while one-step TD is based on one next reward, bootstrapping from the value of the state one step later. n-step TD is the intermediate method, which performs an update based on an intermediate number of rewards, which is more than one but less than all of them.
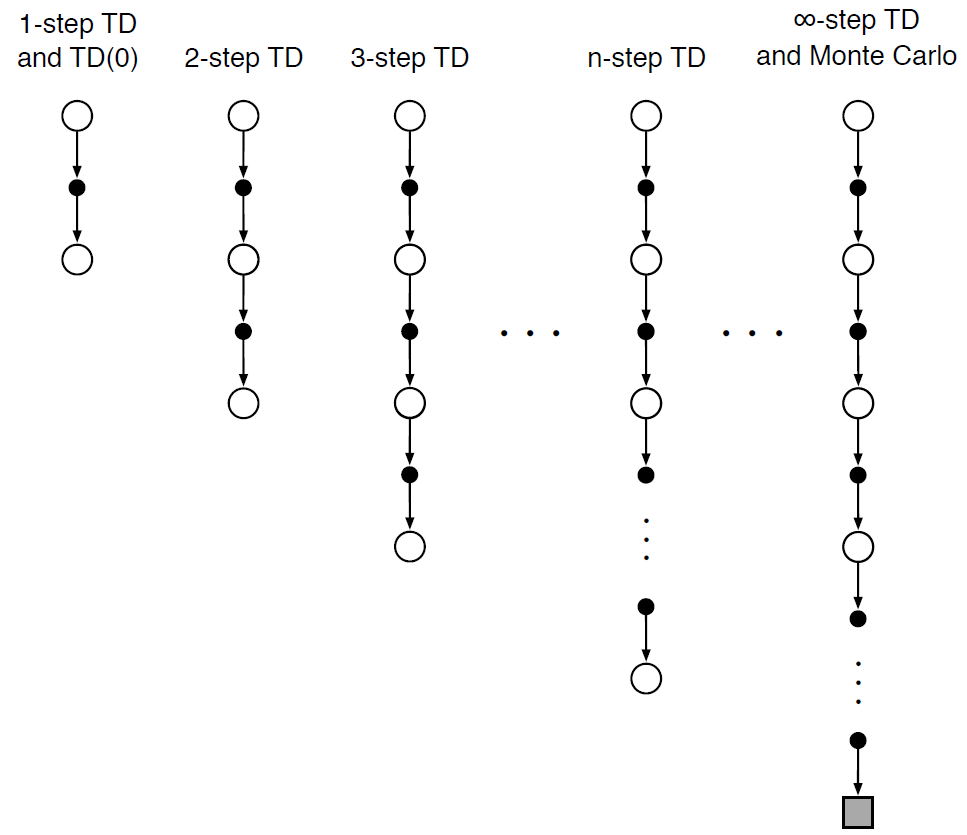
More formally, consider the update of state \(S_t\) with the sequence, \(S_t, R_{t+1}, S_{t+1}, R_{t+2}, ..., R_{T}, S_{T}\). Monte Carlo is updated in the complete return:
\(G_{t} = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... +\gamma^{T-t-1} R_{T}\)
where T is the last time step of the episode. And we have one-step TD return:
\(G_{t:t+1} = R_{t+1} + \gamma V_{t}(S_{t+1})\)
Accordingly, we have n-step TD return:
\(G_{t:t+n} = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... +\gamma^{n-1} R_{t+n} + \gamma^n V_{t+n-1}(S_{t+n})\)
2. How to enable nstep-TD in DI-engine
DI-engine has provided n-step implementation and enable it in a lot of algorithms, like DQN, A2C, etc. Here, we will introduce how to enable nstep-td and modify the code. Takes DQN as an example, if we want to enable nstep=3, we should set the config as follows:
config = dict(
type='dqn',
cuda=False,
on_policy=False,
priority=False,
discount_factor=0.97,
# (int) N-step reward for target q_value estimation
nstep=3,
...,)
3. How does it work in DI-engine
Takes DQN as an example again. We set the propoerty according to the config in _init_collect and
_init_learn function in the corresponding policy. Here we show the code of DQN as follows,
def _init_collect(self) -> None:
...,
self._nstep = self._cfg.nstep
...,
def _init_learn(self) -> None:
...,
self._nstep = self._cfg.nstep
...,
Then, we organize the rewards and value data for n-step return in _get_train_sample function.
def _get_train_sample(self, data: deque) -> Union[None, List[Any]]:
...,
if self._nstep_return:
data = self._adder.get_nstep_return_data(data, self._nstep)
...,
return self._adder.get_train_sample(data)
Next, we actually calculate n-step return in _forward_learn function
def _forward_learn(self, data: dict) -> Dict[str, Any]:
...,
data_n = q_nstep_td_data(
q_value, target_q_value, data['action'], target_q_action, data['reward'], data['done'], data['weight']
)
value_gamma = data.get('value_gamma')
loss, td_error_per_sample = q_nstep_td_error(data_n, self._gamma, nstep=self._nstep, value_gamma=value_gamma)
...,
The calculation is implemented in q_nstep_td_error function
Please notice that the key nstep might be in different positions for different algorithm.
We also provide some other n-sted td methods, please refer to ding\rl_utils\td.py.