DQN¶
Overview¶
DQN was first proposed in Playing Atari with Deep Reinforcement Learning, which combines Q-learning with deep neural network. Different from the previous methods, DQN use a deep neural network to evaluate the q-values, which is updated via TD-loss along with gradient decent.
Quick Facts¶
DQN is a model-free and value-based RL algorithm.
DQN only support discrete action spaces.
DQN is an off-policy algorithm.
Usually, DQN use eps-greedy or multinomial sample for exploration.
DQN + RNN = DRQN.
The DI-engine implementation of DQN supports multi-discrete action space.
Key Equations or Key Graphs¶
The TD-loss used in DQN is:
Pseudo-code¶

Note
Compared with the vanilla version, DQN has been dramatically improved in both algorithm and implementation. In the algorithm part, n-step TD-loss, PER, target network and dueling head are widely used. For the implementation details, the value of epsilon anneals from a high value to zero during the training rather than keeps constant, according to env step(the number of policy interaction with env).
Extensions¶
DQN can be combined with:
PER (Prioritized Experience Replay)
PRIORITIZED EXPERIENCE REPLAY replaces the uniform sampling in replay buffer with a kind of special defined
priority, which is defined by various metrics, such as absolute TD error, the novelty of observation and so on. By this priority sampling, the convergence speed and performance of DQN can be improved a lot.One of implementation of PER is described:

Multi-step TD-loss
Note
In the one-step setting, Q-learning learns \(Q(s,a)\) with the Bellman update: \(r(s,a)+\gamma \mathop{max}\limits_{a^*}Q(s',a^*)\). While in the n-step setting the equation is \(\sum_{t=0}^{n-1}\gamma^t r(s_t,a_t) + \gamma^n \mathop{max}\limits_{a^*}Q(s_n,a^*)\). An issue about n-step for Q-learning is that, when epsilon greedy is adopted, the q value estimation is biased because the \(r(s_t,a_t)\) at t>=1 are sampled under epsilon greedy rather than the policy itself. However, multi-step along with epsilon greedy generally improves DQN practically.
Double (target) network
Double DQN, proposed in Deep Reinforcement Learning with Double Q-learning, is a kind of common variant of DQN. This method maintaines another Q-network, named target network, which is updated by the current netowrk by a fixed frequency(update times).
Double DQN doesn’t select the maximum q_value in the total discrete action space from the current network, but first finds the action whose q_value is highest in the current network, then gets the q_value from the target network according to this selected action. This variant can surpass the over estimation problem of target q_value, and reduce upward bias.
Note
The over estimation can be caused by the error of function approximation(neural network for q table), environment noise, numerical instability and other reasons.
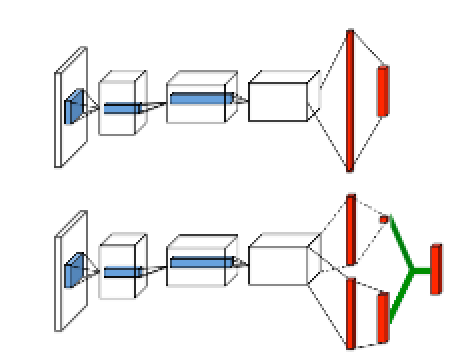
Dueling head
In Dueling Network Architectures for Deep Reinforcement Learning, dueling head architecture is utilized to implement the decomposition of state-value and advantage for taking each action, and use these two parts to construct the final q_value, which is better for evaluating the value of some states not related to action selection.
The specific architecture is shown in the following graph:
RNN (DRQN, R2D2)
Implementations¶
The default config of DQNPolicy is defined as follows:
- class ding.policy.dqn.DQNPolicy(cfg: dict, model: Optional[Union[type, torch.nn.modules.module.Module]] = None, enable_field: Optional[List[str]] = None)[source]
- Overview:
Policy class of DQN algorithm, extended by Double DQN/Dueling DQN/PER/multi-step TD.
- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
dqn
RL policy register name, refer toregistryPOLICY_REGISTRYThis arg is optional,a placeholder2
cudabool
False
Whether to use cuda for networkThis arg can be diff-erent from modes3
on_policybool
False
Whether the RL algorithm is on-policyor off-policy4
prioritybool
False
Whether use priority(PER)Priority sample,update priority5
priority_IS_weightbool
False
Whether use Importance Sampling Weightto correct biased update. If True,priority must be True.6
discount_factorfloat
0.97, [0.95, 0.999]
Reward’s future discount factor, aka.gammaMay be 1 when sparsereward env7
nstepint
1, [3, 5]
N-step reward discount sum for targetq_value estimation8
learn.updateper_collectint
3
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingThis args can be varyfrom envs. Bigger valmeans more off-policy9
learn.batch_sizeint
64
The number of samples of an iteration10
learn.learning_ratefloat
0.001
Gradient step length of an iteration.11
learn.target_update_freqint
100
Frequence of target network update.Hard(assign) update12
learn.ignore_donebool
False
Whether ignore done for target valuecalculation.Enable it for somefake termination env13
collect.n_sampleint
[8, 128]
The number of training samples of acall of collector.It varies fromdifferent envs14
collect.unroll_lenint
1
unroll length of an iterationIn RNN, unroll_len>1
The network interface DQN used is defined as follows:
- class ding.model.template.q_learning.DQN(obs_shape: Union[int, ding.utils.type_helper.SequenceType], action_shape: Union[int, ding.utils.type_helper.SequenceType], encoder_hidden_size_list: ding.utils.type_helper.SequenceType = [128, 128, 64], dueling: bool = True, head_hidden_size: Optional[int] = None, head_layer_num: int = 1, activation: Optional[torch.nn.modules.module.Module] = ReLU(), norm_type: Optional[str] = None)[source]
- __init__(obs_shape: Union[int, ding.utils.type_helper.SequenceType], action_shape: Union[int, ding.utils.type_helper.SequenceType], encoder_hidden_size_list: ding.utils.type_helper.SequenceType = [128, 128, 64], dueling: bool = True, head_hidden_size: Optional[int] = None, head_layer_num: int = 1, activation: Optional[torch.nn.modules.module.Module] = ReLU(), norm_type: Optional[str] = None) → None[source]
- Overview:
Init the DQN (encoder + head) Model according to input arguments.
- Arguments:
obs_shape (
Union[int, SequenceType]): Observation space shape, such as 8 or [4, 84, 84].action_shape (
Union[int, SequenceType]): Action space shape, such as 6 or [2, 3, 3].encoder_hidden_size_list (
SequenceType): Collection ofhidden_sizeto pass toEncoder, the last element must matchhead_hidden_size.dueling (
dueling): Whether chooseDuelingHeadorDiscreteHead(default).head_hidden_size (
Optional[int]): Thehidden_sizeof head network.head_layer_num (
int): The number of layers used in the head network to compute Q value outputactivation (
Optional[nn.Module]): The type of activation function in networks ifNonethen default set it tonn.ReLU()norm_type (
Optional[str]): The type of normalization in networks, seeding.torch_utils.fc_blockfor more details.
- forward(x: torch.Tensor) → Dict[source]
- Overview:
DQN forward computation graph, input observation tensor to predict q_value.
- Arguments:
x (
torch.Tensor): Observation inputs
- Returns:
outputs (
Dict): DQN forward outputs, such as q_value.
- ReturnsKeys:
logit (
torch.Tensor): Discrete Q-value output of each action dimension.
- Shapes:
x (
torch.Tensor): \((B, N)\), where B is batch size and N isobs_shapelogit (
torch.FloatTensor): \((B, M)\), where B is batch size and M isaction_shape
- Examples:
>>> model = DQN(32, 6) # arguments: 'obs_shape' and 'action_shape' >>> inputs = torch.randn(4, 32) >>> outputs = model(inputs) >>> assert isinstance(outputs, dict) and outputs['logit'].shape == torch.Size([4, 6])
The Benchmark result of DQN implemented in DI-engine is shown in Benchmark
Reference¶
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller: “Playing Atari with Deep Reinforcement Learning”, 2013; arXiv:1312.5602. https://arxiv.org/abs/1312.5602