PPG¶
Overview¶
PPG was proposed in Phasic Policy Gradient. In prior methods, one must choose between using a shared network or separate networks to represent the policy and value function. Using separate networks avoids interference between objectives, while using a shared network allows useful features to be shared. PPG is able to achieve the best of both worlds by splitting optimization into two phases, one that advances training and one that distills features.
Quick Facts¶
PPG is a model-free and policy-based RL algorithm.
PPG supports both discrete and continuous action spaces.
PPG supports off-policy mode and on-policy mode.
There is 2 value network in PPG.
In the implementation of DI-engine, we use two buffer to off-policy PPG
Key Graphs¶
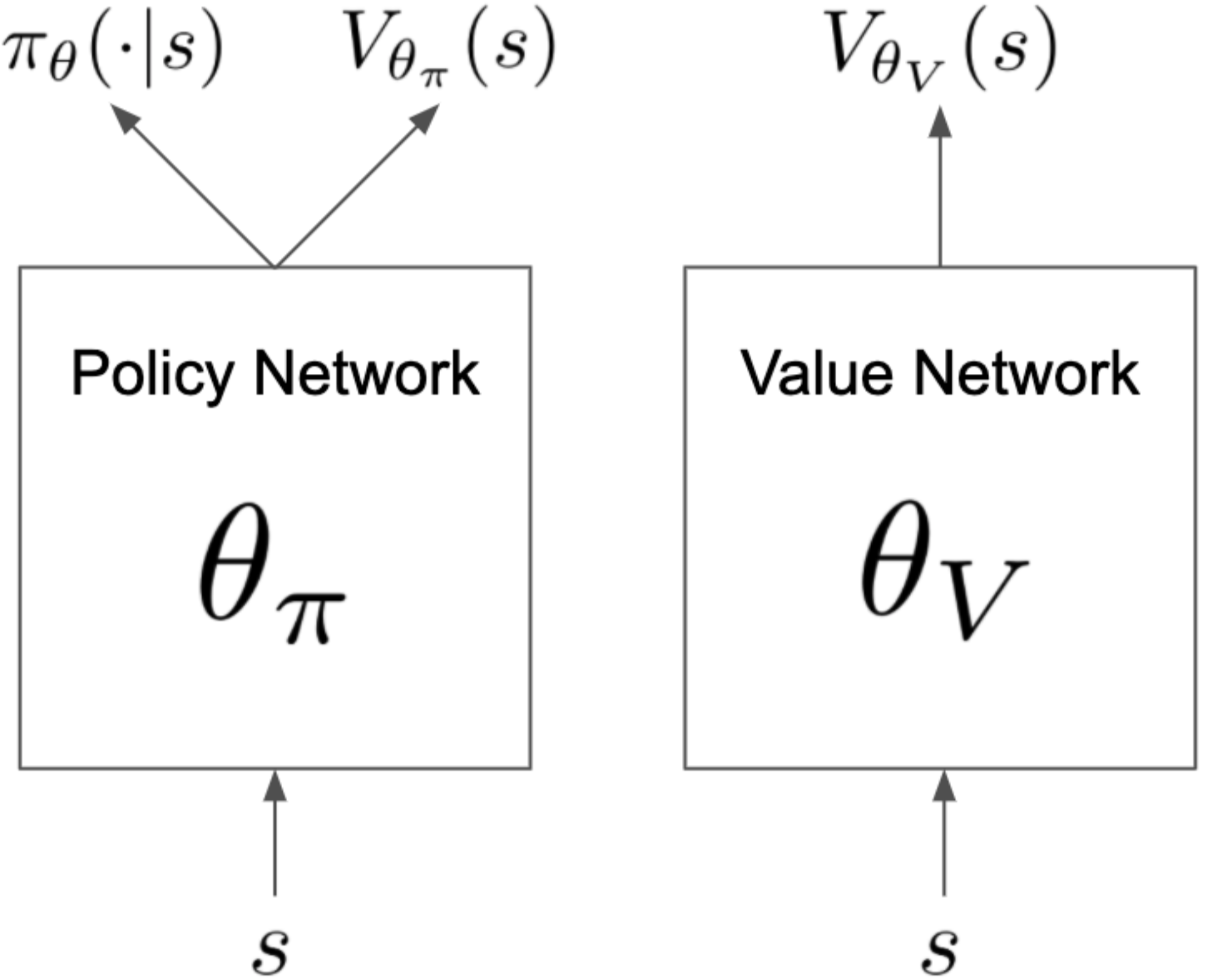
PPG uses disjoint policy and value networks to reduce interference between objectives. The policy network includes an auxiliary value head which is used to distill the knowledge of value into the policy network.
Key Equations¶
The optimization of PPG alternates between two phases, a policy phase and an auxiliary phase. During the policy phase, the policy network and the value network are updated similar to PPO. During the auxiliary phase, the value knowledge is distilled into the policy network with the joint loss:
The joint loss optimizes the auxiliary objective while preserves the original policy with the KL-divergence restriction. The auxiliary loss is defined as:
Pseudo-code¶
The following flow charts shows how PPG alternates between the policy phase and the auxiliary phase.

Note
During the auxiliary phase, PPG also takes the opportunity to perform additional training on the value network.
Extensions¶
- PPG can be combined with:
Multi-step learning
GAE
Multi buffer, different max reuse
Implementation¶
The default config is defined as follows:
- class ding.policy.ppg.PPGPolicy(cfg: dict, model: Optional[Union[type, torch.nn.modules.module.Module]] = None, enable_field: Optional[List[str]] = None)[source]
- Overview:
Policy class of PPG algorithm.
- Interface:
_init_learn, _data_preprocess_learn, _forward_learn, _state_dict_learn, _load_state_dict_learn _init_collect, _forward_collect, _process_transition, _get_train_sample, _get_batch_size, _init_eval, _forward_eval, default_model, _monitor_vars_learn, learn_aux
- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
ppg
POLICY_REGISTRY2
cudabool
False
3
on_policybool
True
prioritybool
False
5
priority_IS_weightbool
False
6
learn.update_per_collectint
5
7
learn.value_weightfloat
1.0
8
learn.entropy_weightfloat
0.01
9
learn.clip_ratiofloat
0.2
10
learn.adv_normbool
False
11
learn.aux_freqint
5
12
learn.aux_train_epochint
6
13
learn.aux_bc_weightint
1
14
collect.discount_factorfloat
0.99
15
collect.gae_lambdafloat
0.95
The network interface PPG used is defined as follows:
The Benchmark result of PPG implemented in DI-engine is shown in Benchmark.
References¶
Karl Cobbe, Jacob Hilton, Oleg Klimov, John Schulman: “Phasic Policy Gradient”, 2020; [http://arxiv.org/abs/2009.04416 arXiv:2009.04416].